


Are Data Engineers Becoming Obsolete?
The Industry Shift No One’s Talking About

And by “no one,” I mean everyone. But here’s what they’re missing:
Data engineering continues to be one of the hottest career tracks. Years ago, many people I admire started abandoning data science (Joe Reis famously fashions himself as a “recovering data scientist”) opting to focus on arguably the most important aspect of data - how to architect and orchestrate an organization's data ecosystem.
But just like other areas of tech, data engineers are becoming increasingly worried their jobs are at risk. With managed services and AI automating more of the technical heavy lifting, it is easy to assume that the role of a data engineer is shrinking.
But that assumption misses the bigger picture.
From my perspective, what is actually happening is what has always happened in tech. These advancements do not signify the death of data engineering, but its evolution. Just as the Database Administrators of the 1980s evolved into the Data Engineers of the 2000s, who in turn became the Big Data Engineers of the 2010s, the data engineers of the 2020s are evolving into something better: the most successful data engineers are becoming Data Orchestrators.
What does that mean? Well, the most valuable data engineers today are not just moving data around. They are getting closer to the business, driving impact, and stepping into an orchestration role to ensure that companies can trust their data and make better decisions.
The future of data engineering is not about writing pipelines. It is about critical thinking, context, and strategy. The best engineers are becoming the maestros of data, ensuring that everything flows together harmoniously, from ingestion to transformation to insights.
But stepping back from the role of data engineer and into the role of data orchestrator is not easy. Let’s dig into it.
This article is sponsored by Matillion, a platform that helps data teams simplify and accelerate data transformation so they can focus on driving business value, not just moving data. They are hosting an event on March 11 about eliminating friction in data workflows. If you want to see where the industry is heading, you can register here.
How We Got Here: The Evolution of Data Engineering
To understand where we’re going, let’s take a look at how data engineering has evolved over the decades.
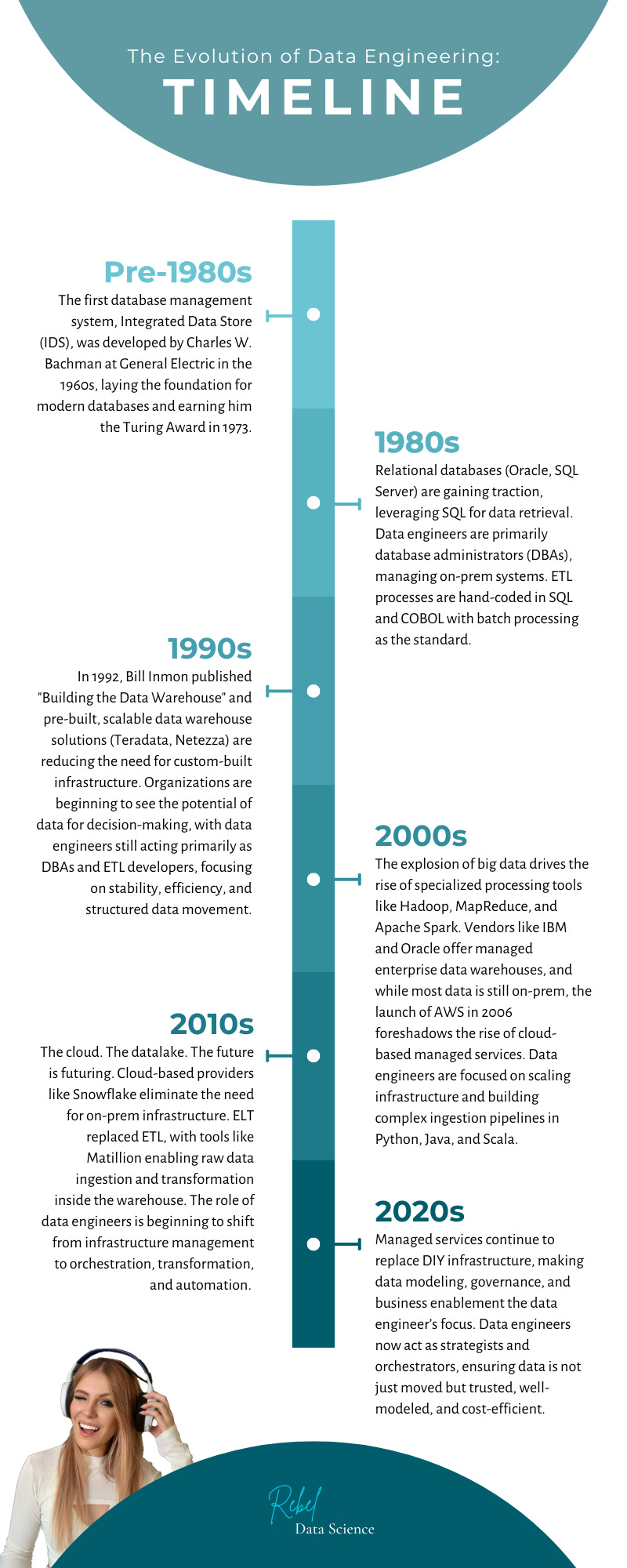
From the rigid, monolithic architectures of the past to the cloud-driven orchestration of today, the role of the data engineer has undergone a complete transformation.
The Data Orchestrator
Don’t judge the cheesy name. Yes, “The Orchestrator” sounds like an end boss in an 80s synthwave video game. But the title “Data Architect” was already taken, so I got creative.
Leave me alone.
And yes, I realize “data orchestration” is already a thing, but I think it actually aligns well with what I am discussing. If data orchestration is the process for taking siloed data from multiple storage locations, combining and organizing it, and making it available for analysis, then the “data orchestrator” mindset reflects just that - moving away from siloed processes and into a big picture view of data.
Anyway… I view the shift from data engineer to what I am calling the “data orchestrator” similar to how database administrators (DBAs) evolved in the 1980s and 1990s.
Back then, DBAs were focused on maintaining relational databases, ensuring performance, indexing, and query optimization. They spent much of their time managing schema changes, tuning SQL queries, and provisioning on-prem hardware. As cloud databases and managed services reduced the need for manual tuning, the DBA role shifted, first towards ETL then again in the 2000s, towards complex infrastructure building and management.
Then, in the 2010s, data engineers spent most of their time building and maintaining increasingly complex data pipelines. Managing Spark clusters, ETL jobs, and Airflow DAGs was a core part of the role, ensuring raw data was processed for analysts and data scientists.
Today, much of that work is handled by managed ingestion and transformation services like Matillion. This doesn’t mean that data engineers are disappearing, it means the focus has shifted.
The challenge is no longer just about moving data but ensuring it is clean, well-modeled, governed, and available in real time to support AI, analytics, and business decision-making.
How AI is Pushing Data Engineers Toward Orchestration
The rise of AI and machine learning has added new complexity to the data stack. Unlike traditional analytics, AI models rely on continuously updated, high-quality data to remain effective.
This means data engineers must think beyond ingestion and transformation to consider:
Data quality and observability to prevent models from using outdated or inconsistent data.
Real-time and event-driven architectures to support AI applications that need fresh data.
Data governance and lineage to ensure sensitive data is properly managed and traceable.
So, think of data orchestrator less as a title and more like a state of mind (I am not helping myself with the cheesiness of this whole thing, am I?).
What we are seeing is just another shift in how data engineers work.
And while I lament the fact that the title “data architect” is already a thing, I do believe there is a difference in the data orchestrator mindset and the role of a data architect. In fact, I think data architects are probably on the front line employing this data orchestrator mindset. They regularly:
Design and optimize data pipelines rather than just build them.
Understand how AI and advanced analytics consume data, rather than just move it.
Ensure data is reliable, trustworthy, and ready for business impact.
Why This Matters for the Future of Data Engineering
Just as DBAs who adapted to cloud databases, governance, and automation remained valuable, data engineers who embrace orchestration, governance, and AI readiness will future-proof their careers.
Orchestration isn’t about doing less, it’s about doing more of what actually matters. Instead of spending time maintaining brittle pipelines, the best engineers will design scalable, automated workflows that support AI-driven decision-making, real-time analytics, and seamless business operations.
The future of data engineering is being shaped in real time, and the best way to stay ahead is to learn from the people defining it.
On March 11, Matillion is hosting a virtual event featuring industry leaders from Snowflake and Hakkoda breaking down how AI, automation, and agentic ETL are transforming data productivity.

Event Details:
📅 Date: Tuesday, March 11, 2025
⏰ Time: 9 AM PT / 12 PM ET / 4 PM GMT
Thanks a ton to Matillion for sponsoring this episode of Good at Business! Not only are they awesome folks to work with, their platform helps data engineers transform into data orchestrators by simplifying and accelerating data transformation so you can focus less on moving data and more on being Good at Business.
And with this also creates a demand for data governance roles
What all skills are added as data governance ?